Welcome to the future of cloud computing. Serverless Computing is revolutionizing how developers build and deploy applications—without managing a single server. It’s fast, scalable, and cost-efficient. Let’s dive deep into what makes it a game-changer.
What Is Serverless Computing?

Despite its name, Serverless Computing doesn’t mean there are no servers. Instead, it means you, as a developer or business, don’t have to worry about provisioning, scaling, or maintaining them. The cloud provider handles all the infrastructure automatically.



No Server Management Required
In traditional computing models, teams spend significant time setting up servers, installing operating systems, configuring firewalls, and applying security patches. With Serverless Computing, all of this disappears. You simply upload your code, and the platform runs it.
- Developers focus solely on writing business logic.
- No need for system administrators to monitor uptime or patch OS vulnerabilities.
- Automatic load balancing and failover mechanisms are built-in.
“Serverless allows developers to move at the speed of innovation, not infrastructure.” — Amazon Web Services
Event-Driven Execution Model
Serverless functions are typically triggered by events—such as an HTTP request, a file upload to cloud storage, or a message in a queue. This event-driven architecture makes Serverless Computing ideal for microservices, real-time data processing, and automation workflows.
- Functions execute only when needed, reducing idle time.
- Supports asynchronous processing for background tasks like image resizing or email notifications.
- Integrates seamlessly with other cloud services via APIs.
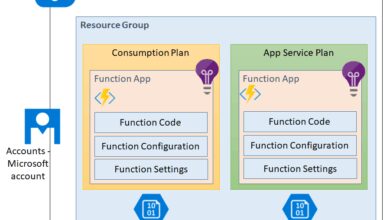
How Serverless Computing Works
Understanding the mechanics behind Serverless Computing helps demystify its power. At its core, it relies on Function-as-a-Service (FaaS), where small units of code (functions) are executed in ephemeral containers.
Function-as-a-Service (FaaS) Explained
FaaS is the backbone of Serverless Computing. Platforms like Azure Functions, Google Cloud Functions, and AWS Lambda allow developers to deploy individual functions that respond to specific triggers.
- Each function is stateless and runs in isolation.
- Lifecycle is short—functions start, execute, and terminate quickly.
- Scaling happens automatically; hundreds of instances can run simultaneously if needed.
Execution Environment and Cold Starts
When a function is invoked, the cloud provider spins up an execution environment. If no instance is running (a “cold start”), there can be a slight delay while the container initializes. This is one of the key performance considerations in Serverless Computing.
- Cold starts affect latency, especially for infrequently used functions.
- Providers use techniques like container reuse and provisioned concurrency to mitigate this.
- Proper function design (smaller packages, efficient initialization) reduces cold start impact.
Key Benefits of Serverless Computing
Organizations are rapidly adopting Serverless Computing due to its compelling advantages over traditional architectures. Let’s explore the most impactful benefits.
Cost Efficiency and Pay-Per-Use Model
One of the biggest draws of Serverless Computing is its pricing model. You only pay for the compute time your code actually consumes—measured in milliseconds. There’s no charge when your function isn’t running.
- Eliminates costs associated with idle servers.
- Ideal for applications with variable or unpredictable traffic.
- Reduces operational overhead and capital expenditure.
According to a Gartner report, serverless can reduce cloud costs by up to 70% compared to always-on virtual machines.
Automatic Scaling and High Availability
Serverless platforms automatically scale your application in response to incoming traffic. Whether you get one request per day or thousands per second, the system handles it seamlessly.
- No manual intervention required for scaling.
- Built-in redundancy across availability zones ensures high availability.
- Perfect for handling traffic spikes during promotions or viral events.
Rapid Development and Deployment
With Serverless Computing, development cycles are faster. Teams can deploy functions independently, enabling continuous integration and continuous deployment (CI/CD) at scale.
- Smaller codebases are easier to test and debug.
- Supports agile methodologies and DevOps practices.
- Integration with tools like GitHub Actions and Jenkins streamlines automation.
Common Use Cases for Serverless Computing
Serverless Computing isn’t just a buzzword—it’s being used in real-world applications across industries. Here are some of the most effective use cases.
Real-Time File Processing
When a user uploads an image, video, or document to cloud storage, a serverless function can automatically process it—resizing images, extracting metadata, or converting file formats.
- Example: Automatically generate thumbnails when a photo is uploaded to Amazon S3.
- Uses: Media platforms, e-commerce sites, content management systems.
- Benefits: Fast processing, low latency, no need for dedicated processing servers.
Web and Mobile Backend Services
Serverless functions can serve as lightweight backends for web and mobile apps, handling API requests, user authentication, and database interactions.
- Example: A mobile app uses AWS Lambda to authenticate users via Amazon Cognito.
- Uses: Single-page applications (SPAs), progressive web apps (PWAs), IoT device management.
- Benefits: Reduced backend complexity, faster time-to-market.
Data Stream Processing and Analytics
Serverless Computing excels at processing streaming data from sources like IoT devices, logs, or clickstreams. Functions can analyze data in real time and trigger alerts or store insights in databases.
- Example: Analyze sensor data from smart thermostats to detect anomalies.
- Uses: Predictive maintenance, fraud detection, real-time dashboards.
- Benefits: Immediate response to events, scalable data ingestion.
Challenges and Limitations of Serverless Computing
While Serverless Computing offers many advantages, it’s not a one-size-fits-all solution. Understanding its limitations is crucial for making informed architectural decisions.
Vendor Lock-In and Portability Issues
Most serverless platforms are tightly integrated with their respective cloud ecosystems. Migrating functions from AWS Lambda to Google Cloud Functions often requires significant code changes.
- Different providers have unique APIs, triggers, and configuration formats.
- Using open-source frameworks like Serverless Framework or Fn Project can improve portability.
- Adopting container-based solutions like AWS Fargate may offer more flexibility.
Debugging and Monitoring Complexity
Traditional debugging tools don’t always work well in serverless environments. Logs are distributed, functions are short-lived, and reproducing issues locally can be difficult.
- Requires specialized monitoring tools like Datadog, Thundra, or AWS CloudWatch.
- Distributed tracing becomes essential for tracking function calls across services.
- Investing in observability platforms improves troubleshooting efficiency.
Execution Time and Resource Limits
Cloud providers impose limits on function execution duration, memory, and package size. For example, AWS Lambda functions can run for a maximum of 15 minutes.
- Not suitable for long-running batch jobs or heavy computations.
- Memory is capped (up to 10 GB on AWS), limiting performance for memory-intensive tasks.
- Solutions include breaking large tasks into smaller functions or using containers for extended workloads.
Serverless Computing vs. Traditional Architectures
To truly appreciate the value of Serverless Computing, it’s helpful to compare it with traditional server-based models like virtual machines (VMs) and containers.
Serverless vs. Virtual Machines
VMs require provisioning, ongoing maintenance, and are often underutilized. In contrast, Serverless Computing abstracts away the entire infrastructure layer.
- VMs: You manage OS, security, scaling, and patching.
- Serverless: Provider manages everything; you only write code.
- Cost: VMs charge per hour, even when idle; serverless charges per millisecond of execution.
Serverless vs. Containers (e.g., Kubernetes)
Containers offer more control and portability than serverless, but they come with operational complexity. Orchestrating containers with Kubernetes requires expertise in networking, scaling, and service discovery.
- Containers: Great for monolithic apps or when you need full control over the environment.
- Serverless: Best for event-driven microservices with variable workloads.
- Hybrid approach: Use serverless for APIs and background jobs, containers for stateful services.
Best Practices for Implementing Serverless Computing
Adopting Serverless Computing successfully requires more than just deploying functions. Following best practices ensures reliability, security, and maintainability.
Design Functions Around Single Responsibilities
Just like in microservices, each serverless function should do one thing well. This improves testability, reusability, and scalability.
- Avoid monolithic functions that handle multiple tasks.
- Use function chaining or workflows (e.g., AWS Step Functions) for complex processes.
- Keep deployment packages small to reduce cold start times.
Secure Your Serverless Applications
Security in Serverless Computing shifts from infrastructure to code and configuration. Misconfigured permissions or exposed APIs can lead to breaches.
- Apply the principle of least privilege using IAM roles and policies.
- Validate and sanitize all inputs to prevent injection attacks.
- Use encryption for data at rest and in transit.
Optimize Performance and Reduce Latency
Performance tuning in serverless involves balancing memory, timeout settings, and execution environment.
- Increase allocated memory to improve CPU performance (AWS ties CPU to memory).
- Use provisioned concurrency to keep functions warm for critical paths.
- Leverage caching (e.g., Redis or DynamoDB TTL) to avoid repeated computations.
The Future of Serverless Computing
Serverless Computing is still evolving, with new capabilities emerging every year. From edge computing to AI integration, the trajectory points toward even greater abstraction and efficiency.
Edge Computing and Serverless at the Edge
Providers are bringing serverless functions closer to users through edge networks. AWS Lambda@Edge, Cloudflare Workers, and Azure Functions on Edge enable low-latency execution for global applications.
- Run code in CDN locations worldwide.
- Use cases: Personalized content delivery, bot detection, A/B testing.
- Reduces round-trip time to origin servers.
Integration with AI and Machine Learning
Serverless functions are increasingly used to serve machine learning models or trigger AI workflows. For example, a function can invoke a model to classify images uploaded to cloud storage.
- Use SageMaker endpoints triggered by Lambda functions.
- Process natural language queries in real time using serverless APIs.
- Enable event-driven AI pipelines without managing inference servers.
Standardization and Open Source Momentum
As adoption grows, efforts to standardize serverless interfaces are gaining traction. Projects like Knative (on Kubernetes) aim to create a portable serverless platform across clouds.
- Reduces vendor lock-in concerns.
- Enables hybrid and multi-cloud serverless deployments.
- Promotes interoperability between different FaaS providers.
What is Serverless Computing?
Serverless Computing is a cloud computing model where developers run code without managing servers. The cloud provider dynamically allocates resources and scales the application automatically, charging only for actual execution time.
Is Serverless Computing really serverless?
No, servers still exist, but they are fully managed by the cloud provider. Developers don’t need to provision, scale, or maintain them, hence the term “serverless.”
When should I not use Serverless Computing?
Avoid serverless for long-running processes, high-frequency microservices with low latency requirements, or applications requiring specialized hardware. It’s also less ideal if you need full control over the OS or runtime environment.
Which cloud providers offer Serverless Computing?
Major providers include Amazon Web Services (AWS Lambda), Microsoft Azure (Azure Functions), Google Cloud (Cloud Functions), IBM Cloud (Code Engine), and Alibaba Cloud (Function Compute).
How does Serverless Computing reduce costs?
It uses a pay-per-use model, charging only for the milliseconds your code runs. There are no costs for idle servers, leading to significant savings for sporadic or unpredictable workloads.
Serverless Computing is transforming how we build and deploy software. By eliminating infrastructure management, enabling automatic scaling, and offering cost-efficient pricing, it empowers developers to focus on innovation. While challenges like cold starts, vendor lock-in, and debugging complexity remain, the benefits far outweigh the drawbacks for many use cases. As the technology matures—with advancements in edge computing, AI integration, and open standards—Serverless Computing is poised to become the default choice for modern application development. Whether you’re building a simple webhook or a complex data pipeline, embracing serverless can accelerate your journey to the cloud.
Further Reading: