Imagine building complex data pipelines without writing a single line of code. With Azure Data Factory, that’s not just possible—it’s seamless. This powerful cloud-based service transforms how businesses move, process, and orchestrate data at scale.
What Is Azure Data Factory?

Azure Data Factory (ADF) is Microsoft’s cloud-based data integration service that enables organizations to create data-driven workflows for orchestrating and automating data movement and data transformation. It allows you to ingest data from multiple sources, transform it using compute services like Azure Databricks or HDInsight, and deliver it to destinations such as data warehouses or analytics platforms.



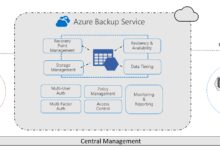
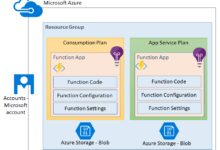
Core Purpose and Use Cases
Azure Data Factory is designed for ETL (Extract, Transform, Load), ELT (Extract, Load, Transform), and data integration scenarios across hybrid and multi-cloud environments. Common use cases include:
- Migrating on-premises databases to the cloud
- Building enterprise data lakes
- Orchestrating machine learning pipelines
- Automating reporting and analytics workflows
“Azure Data Factory is the backbone of modern data integration in the Microsoft Azure ecosystem.” — Microsoft Azure Documentation
How It Fits in the Azure Ecosystem
Azure Data Factory integrates seamlessly with other Azure services such as Azure Blob Storage, Azure SQL Database, Azure Synapse Analytics, and Azure Databricks. It acts as the orchestration layer that connects data sources, processing engines, and destination systems, enabling end-to-end data workflows.
For example, ADF can pull raw data from an IoT hub, trigger an Azure Function to clean the data, run transformations in Azure Databricks, and load the results into Power BI for visualization—all without manual intervention.
Key Components of Azure Data Factory
To understand how Azure Data Factory works, you need to be familiar with its core components. These building blocks allow you to design, deploy, and monitor data pipelines effectively.
Pipelines and Activities
A pipeline in Azure Data Factory is a logical grouping of activities that perform a specific task. For instance, a pipeline might extract data from Salesforce, transform it using a stored procedure in Azure SQL, and load it into a data warehouse.
Activities are the individual actions within a pipeline and fall into three main categories:
- Data movement activities: Copy data between sources and sinks.
- Data transformation activities: Use services like Azure Databricks, HDInsight, or Azure Functions to process data.
- Control activities: Manage workflow logic (e.g., If Condition, ForEach, Execute Pipeline).
Linked Services and Datasets
Linked services define the connection information needed to connect to external resources. Think of them as connection strings that specify the endpoint, authentication method, and credentials for data stores or compute services.
Datasets, on the other hand, represent the structure of the data within those linked services. They define what data to use—such as a specific table in SQL Server or a folder in Azure Blob Storage.
For example, a linked service might connect to an Azure SQL Database, while a dataset defines which table in that database should be used in a pipeline.
Integration Runtime
The Integration Runtime (IR) is the compute infrastructure that Azure Data Factory uses to provide data integration capabilities across different network environments. There are three types:
- Azure Integration Runtime: Used for public cloud data movement and transformation.
- Self-hosted Integration Runtime: Enables data transfer between cloud and on-premises systems.
- Managed Virtual Network Integration Runtime: Used for secure data processing within a managed virtual network.
The self-hosted IR is particularly useful when dealing with legacy systems behind firewalls or in private networks.
Azure Data Factory vs. Traditional ETL Tools
Compared to traditional ETL tools like Informatica or SSIS, Azure Data Factory offers several advantages, especially in scalability, cost, and cloud-native integration.
Cloud-Native Architecture
Unlike on-premises ETL tools, Azure Data Factory is fully cloud-native. This means no hardware provisioning, automatic scaling, and high availability built-in. You pay only for what you use, and the service scales elastically based on workload demands.
Traditional tools often require dedicated servers, regular maintenance, and manual scaling, which increases operational overhead.
Serverless Data Integration
Azure Data Factory operates in a serverless model. You don’t manage any infrastructure—Microsoft handles the underlying compute. This allows data engineers to focus on pipeline logic rather than system administration.
In contrast, tools like SSIS require deployment on SQL Server instances or Integration Services Catalogs, which involve more setup and monitoring.
Native Integration with Azure Services
Azure Data Factory has deep integration with Azure services such as Azure Databricks, Azure Synapse Analytics, and Azure Functions. This tight coupling makes it easier to build modern data architectures like data lakes and real-time analytics pipelines.
Traditional tools may require custom connectors or middleware to achieve similar integration.
Building Your First Pipeline in Azure Data Factory
Creating a pipeline in Azure Data Factory is a straightforward process using the Azure portal’s visual interface, known as the Data Factory UX.
Step-by-Step Pipeline Creation
Here’s how to create a simple data copy pipeline:
- Step 1: Log in to the Azure portal and create a new Data Factory resource.
- Step 2: Open the Data Factory Studio (formerly authoring UI).
- Step 3: Create linked services for your source (e.g., Azure Blob Storage) and sink (e.g., Azure SQL Database).
- Step 4: Define datasets that reference these linked services.
- Step 5: Create a new pipeline and add a Copy Data activity.
- Step 6: Configure the source and sink datasets in the activity.
- Step 7: Debug or publish the pipeline to run it.
This visual approach reduces the need for coding and makes pipeline development accessible to non-developers.
Using Data Flow for Code-Free Transformations
Azure Data Factory includes a feature called Mapping Data Flows, which allows you to perform transformations using a drag-and-drop interface. It runs on Spark under the hood, so you get scalable, serverless data transformation without writing code.
You can perform operations like filtering, joining, aggregating, and deriving columns visually. The engine automatically generates the Spark code and executes it in a managed environment.
Monitoring and Debugging Pipelines
Once a pipeline is running, you can monitor its execution in the Monitor tab of Data Factory Studio. You can view run history, check for failures, and inspect input/output details.
The Debug mode allows you to test pipelines without publishing them, making it easier to catch errors early. You can also set breakpoints and view data at each activity.
Advanced Features of Azure Data Factory
Beyond basic data movement, Azure Data Factory offers advanced capabilities that empower complex data orchestration.
Trigger-Based Automation
Azure Data Factory supports multiple types of triggers to automate pipeline execution:
- Schedule triggers: Run pipelines on a recurring schedule (e.g., daily at 2 AM).
- Tumbling window triggers: Ideal for time-based data processing, ensuring data is processed in fixed intervals.
- Event-based triggers: Start pipelines when a file is added to Blob Storage or an event is published to Event Grid.
These triggers enable real-time and batch processing scenarios alike.
Parameterization and Reusability
Pipelines in Azure Data Factory can be parameterized, allowing you to reuse them with different inputs. For example, you can create a generic pipeline that copies data from any source to any destination by passing parameters like source path and table name.
This reduces duplication and improves maintainability across large-scale data environments.
Git Integration and CI/CD
Azure Data Factory supports Git integration for version control. You can connect your factory to Azure Repos or GitHub, enabling team collaboration and change tracking.
Combined with Azure DevOps, you can set up CI/CD pipelines to promote Data Factory changes from development to production environments seamlessly.
Security and Compliance in Azure Data Factory
Security is a top priority when handling sensitive data, and Azure Data Factory provides robust mechanisms to ensure data protection and regulatory compliance.
Authentication and Access Control
Azure Data Factory integrates with Azure Active Directory (AAD) for identity management. You can assign roles like Contributor, Reader, or custom roles using Azure RBAC (Role-Based Access Control).
For data stores, ADF supports various authentication methods including service principals, managed identities, and SAS tokens, ensuring secure access without exposing credentials.
Data Encryption and Network Security
All data in transit is encrypted using HTTPS/TLS. Data at rest is encrypted by the underlying Azure storage services (e.g., Azure Blob Storage uses AES-256 encryption).
You can also use Private Endpoints to connect Data Factory to your virtual network, preventing data from traversing the public internet.
Compliance and Auditing
Azure Data Factory complies with major standards such as GDPR, HIPAA, ISO 27001, and SOC 2. Audit logs are available through Azure Monitor and Log Analytics, allowing you to track who accessed what and when.
This is crucial for organizations in regulated industries like healthcare, finance, and government.
Performance Optimization and Best Practices
To get the most out of Azure Data Factory, it’s important to follow performance best practices and optimize your pipelines.
Optimizing Copy Activity Performance
The Copy Activity is the most used activity in ADF. To maximize throughput:
- Use polybase when loading data into Azure Synapse Analytics.
- Enable compression for large files to reduce transfer time.
- Adjust parallel copy settings (number of data integration units) based on source and sink capabilities.
- Use staging with Azure Blob Storage when copying between two cloud services in different regions.
Monitoring copy performance through the ADF portal helps identify bottlenecks.
Managing Data Skew and Throttling
Some data sources may throttle requests or have uneven data distribution. To handle this:
- Implement retry policies with exponential backoff.
- Use partitioning to split large datasets into smaller chunks.
- Leverage the Wait activity to introduce delays between high-load operations.
These strategies prevent pipeline failures due to rate limiting or resource exhaustion.
Cost Management and Monitoring
Azure Data Factory pricing is based on activity runs, data movement, and data integration units (DIUs). To control costs:
- Use auto-resolving integration runtimes for cloud-only scenarios.
- Monitor pipeline execution duration and frequency.
- Use Azure Cost Management to track spending and set budgets.
- Avoid unnecessary debug runs in production environments.
Regularly reviewing usage patterns helps optimize resource allocation.
Real-World Use Cases of Azure Data Factory
Azure Data Factory is used across industries to solve real business problems. Here are some practical examples.
Retail: Unified Customer Analytics
A retail company uses Azure Data Factory to combine sales data from POS systems, e-commerce platforms, and CRM tools into a centralized data lake. The pipeline runs nightly, enriches customer data with demographics, and feeds it into Power BI for dashboards.
This enables personalized marketing and inventory forecasting based on unified customer behavior.
Healthcare: Patient Data Integration
A hospital network uses ADF to securely transfer patient records from on-premises systems to Azure Health Data Services. The pipeline anonymizes sensitive data, validates formats, and triggers alerts for incomplete records.
This ensures compliance with HIPAA while enabling faster access to patient data for clinicians.
Finance: Risk Reporting Automation
A global bank uses Azure Data Factory to automate its daily risk reporting. The pipeline pulls transaction data from multiple regions, applies fraud detection models via Azure Machine Learning, and generates regulatory reports in PDF format.
The entire process, which used to take hours manually, now completes in under 30 minutes.
What is Azure Data Factory used for?
Azure Data Factory is used for orchestrating and automating data movement and transformation workflows in the cloud. It enables ETL/ELT processes, data integration across hybrid environments, and building data pipelines for analytics, machine learning, and reporting.
Is Azure Data Factory a ETL tool?
Yes, Azure Data Factory is a cloud-based ETL (Extract, Transform, Load) and ELT tool. While it excels at data orchestration and movement, it can also perform transformations using integrated services like Azure Databricks, Data Lake Analytics, or Mapping Data Flows.
How much does Azure Data Factory cost?
Azure Data Factory pricing is based on two models: Data Factory v2 (pay-per-use) and Data Factory v1 (legacy). In the v2 model, you pay for pipeline activity runs, data movement, and data integration units (DIUs). There is a free tier with limited monthly activity runs. Exact costs depend on usage volume and region.
Can Azure Data Factory replace SSIS?
Yes, Azure Data Factory can replace SSIS in many scenarios, especially for cloud and hybrid data integration. Microsoft provides the SSIS Integration Runtime to migrate existing SSIS packages to ADF, allowing organizations to modernize their ETL workflows without rewriting everything from scratch.
How does Azure Data Factory integrate with Power BI?
Azure Data Factory does not directly connect to Power BI, but it feeds data into data stores that Power BI can consume—such as Azure SQL Database, Synapse Analytics, or Data Lake Storage. Once data is loaded and transformed by ADF, Power BI can connect to these sources to create visualizations and reports.
Azure Data Factory is more than just a data movement tool—it’s a powerful orchestration engine that empowers organizations to build scalable, secure, and automated data pipelines. Whether you’re migrating legacy systems, building a data lake, or enabling real-time analytics, ADF provides the flexibility and integration needed in today’s data-driven world. By leveraging its visual interface, serverless architecture, and deep Azure ecosystem integration, teams can accelerate data projects and deliver insights faster than ever before.
Recommended for you 👇
Further Reading:



